
티스토리 뷰

PDF 문서 OCR 하는 법 | Free PDF OCR(ocrmypdf)
스캐너로 스캔 한 이미지로 PDF로 만든 경우, PDF 문서 내에서 단어로 검색할 수 없습니다. 스캔 된 이미지에서 문자를 별도로 인식시켜서 TEXT LAYER를 만들어주는 OCR 작업이 필요합니다. 주로 유료 PDF Editor 프로그램에서 제공되는 기능인데 Linux를 이용하면 쉽게 OCR이 적용된 PDF를 만들 수 있습니다.
Windows 10에 WSL2 및 Windows Store에서 Ubuntu 또는 Kali linux를 설치해서 사용 가능합니다.
혹시, 리눅스 설치법이 궁금하시면 제 블로그에서 Ubuntu 또는 Kali Linux로 검색하시면 관련 자료들을 확인하실 수 있습니다.
ocrmypdf 설치법
2가지 프로그램과 언어팩 설치가 먼저 필요합니다.
ocrmypdf 설치를 위해서 sudo apt-get install ocrmypdf를 입력해서 설치합니다.
다음으로 tesseract 설치가 필요합니다. sudo apt-get install tesseract를 입력해서 설치합니다.
apt-cache search tesseract-ocr 명령어를 입력해보면, 이용 가능한 다양한 언어팩을 확인할 수 있습니다.

tesseract 한국어 언어팩

apt-cache search tesseract-ocr | grep "kor" 명령어로 "kor"이 들어간 언어팩만 listing 했습니다. 이 2개 언어팩을 설치하시면 됩니다. 추가로 필요한 언어는 얼마든지 추가로 설치해도 됩니다.
명령어: sudo apt-get install tesseract-ocr-kor

명령어: sudo apt-get install tesseract-ocr-kor-vert
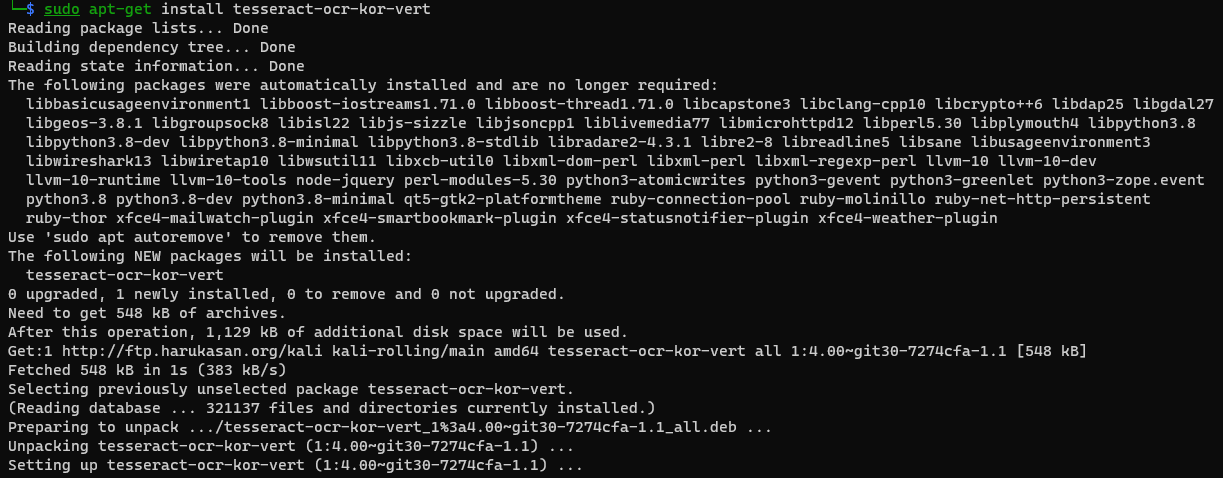
tesseract 설치된 언어팩 확인
명령어: tesseract --list-langs

해당 명령어를 사용해서 정상적으로 eng, kor, kor_vert와 같은 언어팩의 설치 여부를 확인합니다.
ocrmypdf 사용법

명령어: ocrmypdf -l eng+kor input.pdf output.pdf
위와 같이 -l 뒤에는 사용될 언어팩을 옵션으로 지정해 주고, 다음으로 원본 input.pdf 마지막에 출력시킬 output.pdf 명을 지정해서 실행하면 됩니다.
이미지의 해상도가 낮은 경우 마지막에 --oversample 300 과같이 임의로 해상도를 조금 높여줄 수 있습니다. 설명에는 OCR 인식률이 조금 올라간다고 하는데 OCR이 필요한 문서의 경우 스캔할 때부터 해상도를 300DPI 이상으로 스캔하는 것이 좋습니다.


gscan2pdf (GUI) - OCR
리눅스 CLI 환경에서 작업하는 것이 익숙하지않은 사용자는 리눅스 GUI 환경에서 사용할 수 있는 gscan2pdf 프로그램을 설치해서 사용할 수 있습니다.
명령어: sudo apt-get install gscan2pdf


OCR Engine은 Tesseract이며, Language pack 역시 ocrmypdf에서 사용하는 것과 동일합니다. 따라서 추가적으로 언어팩이 필요한 분은 위에서 언급한 언어팩 설치 부분을 참고하시면 됩니다.
'Computer' 카테고리의 다른 글
| 브로드밴드 포트 포워딩 총정리 (5) | 2021.04.26 |
|---|---|
| TacsOnline_PF 금융 - 프라이버시 클린서비스 내역 (0) | 2021.04.26 |
| 방화벽에서 이 앱의 일부 기능을 차단했습니다 | 점검 및 해결 방법 (2) | 2021.04.21 |
| 일베 차단 및 유해 사이트 차단 (1) | 2021.04.17 |
| PDF 민감한 내용 가리기 | Redact(Black Marking) on PDF (0) | 2021.04.02 |
| iso image 만들기 | How to make an iso image (0) | 2021.03.30 |
| PDF를 PSD 파일로 변환하기 / PDF to PSD (0) | 2021.03.30 |
| PUA:Win32/QBitTorrent (1) | 2021.03.27 |
- IP 추적 프로그램
- 암호화 컨테이너
- cc4-202-00000008
- iA Writer
- 무료 동기화 프로그램
- FTP SERVER PORT FORWARDING
- Set Password for PDF
- FREE OFFICE SOFTWARE
- PDF 가리기
- netstat 사용법
- 1일1식
- Windows Pro 암호화
- PDF 문서 만들기
- 티스토리챌린지
- ftp server
- cloudflare dns
- 폴더 암호화
- 전라북도 맛집
- 간헐적단식
- KEX Error
- Kali Linux 활용법
- docuprint m115b scanner
- Windows defender application guard
- Markdown Editor
- 오블완
- 무료 오피스 프로그램
- 고추농사
- certutil
- 무료 데이터 복구
- pdf 비밀번호 설정
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |